Tuesday, October 31, 2017
Face Processing in Japanese and Sign Language Speakers
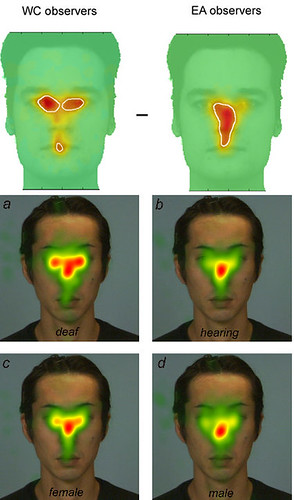
Roberto Caldara and associates find that when recognising faces, Westerners tend to triangulate (in a manner of speaking) analysing the face moving their gaze from eye to eye to mouth, whereas East Asians seem to process faces globally and holistically, perhaps, by focusing upon the nose (upper two images, Miellet, Vizioli, He, Zhou, & Caldara, 2013, p.6).
Bearing in mind that in Lubna Ahmed as yet unpublished research, showing that repeating numbers impedes Westeners but does not reduce the facial processing ability of Japanese, and that repeating numbers impedes analytical but does not impede global processing of Navon figures (Ahmed & W de Fockert, 2012) , conversely improving global recognition, and crossing these results with the fact that research repeating the alphabet is the way of preventing self-talk (Kim, 2002), I presumed that all this demonstrated that East Asian global/holistic face processing is also non-linguistic processing, or conversely that Western triangulation is linguistic processing -- looking for nameable features -- which is impeded by being made to remember and presumably repeat numbers.
Caldera also introduces research (lower four images above from Watanabe, Matsuda, Nishioka, & Namatame, 2011, p.4) that demonstrates that the deaf and women are more likely to use the Western, 'triangulating' style of facial processing, whereas non-deaf and males seem to use the global style method of focussing on the nose. Noted elsewhere the Japanese should resemble the deaf if they are really not whispering -- thinking in words. So why is it that the deaf are using the Western style of face processing?
I think that this further reversal is due to the type of information being processed. The upper image is of Westerner and East Asians recognising the identities of faces whereas the lower four images are of deaf and non deaf, males and females processing emotions.
Emotions and identities may be being processed in opposite ways. As Caldera and colleagues point out (Stoll et al., 2017) the deaf use their faces to speak, so facial expressions and perhaps also emotions of the deaf are more likely to be processed linguistically using the triangulation method. Identities on the other hand are seen as linguistic by Westerners and the non-deaf who process the identities of faces in such a way as enwordify them, where as the Japanese (and I predict the deaf) see identify in the face itself (Watsuji, 2011). In other words, if Matsuda, Nishioka, & Namatame repeated their research except asking deaf and hearing subjects to identify facial identities, I predict they would have found the opposite tendency.
Caldera has further also performed some further fascinating research (Stoll et al., 2017) that finds that both deaf and non-deaf people who use sign language process faces in a different way.
Bingo.
I think that this explains the meaning of Kata, the forms used in everything from Karate to tea ceremony, by which I presume Japanese learn to be Japanese (based on hints from Masamune, Butler, 1993; and Yamamoto, 2009). Kata forms are like sign language by means of which the Japanese learn to speak with their bodies. The Japanese speak at shrines where they clap, and in the kata of martial arts and tea ceremony training rooms, with their bodies. The Japanese have bodies that speak. For the Japanese, this allows them to realise that speaking takes place on the outside of the head, on the forehead even, and this may be how the curse, of the whispering, can be lifted.
I am always attempting to leap to the conclusion.
And, there is a problem with the above line of reasoning in that Lubna Ahmed's unpublished research which showed that repeating numbers did not impede Japanese facial recognition, was upon the recognition of emotions in faces. According to the above reasoning, it is the Japanese who should be impeded if, like the deaf, they are processing emotion in an analytical way.
However, that the differences exhibited by Westerners and East Asians are beginning to be demonstrated in differences between deaf and hearing, and people memorising digits and those who are not, suggests at least tentative support for the Nacalian turn.
Images are from upper two images, Miellet, Vizioli, He, Zhou, & Caldara, 2013, p.6 and Watanabe, Matsuda, Nishioka, & Namatame, 2011, p.4.
お取り下げご希望の場合は下記のコメント欄か、http://nihonbunka.comで掲示されるメールアドレスにご一筆ください。 Should anyone want me to cease and desist, please leave a comment or contact me from the email link at nihonbunka.com
Bibliography
Ahmed, L., & W de Fockert, J. (2012). Working Memory Load Can Both Improve and Impair Selective Attention: Evidence from the Navon Paradigm. Attention, Perception & Psychophysics, 74, 1397–405. doi.org/10.3758/s13414-012-0357-1
Butler, J. (1993). Bodies That Matter: On the Discursive Limits of "Sex. Routledge.
Miellet, S., Vizioli, L., He, L., Zhou, X., & Caldara, R. (2013). Mapping Face Recognition Information Use across Cultures. Frontiers in Psychology, 4, 34. doi.org/10.3389/fpsyg.2013.00034
Stoll, C., Palluel-Germain, R., Caldara, R., Lao, J., Dye, M. W. G., Aptel, F., & Pascalis, O. (2017). Face Recognition is Shaped by the Use of Sign Language. The Journal of Deaf Studies and Deaf Education, 1–9. doi.org/10.1093/deafed/enx034
Watanabe, K., Matsuda, T., Nishioka, T., & Namatame, M. (2011). Eye Gaze during Observation of Static Faces in Deaf People. PLOS ONE, 6(2), e16919. doi.org/10.1371/journal.pone.0016919
Watsuji, T. (2011). Mask and Persona. Japan Studies Review, 15, 147–155.
Yamamoto, I., 山本一輝. (2009). メンタルトレーニング~弓道を通じた自己イメージのあり方~(Mental Training: The way of self imaging achieved through Japanese Archery) (未発表卒論). 山口大学経済学部観光政策学科.
Labels: japanese culture, Nacalian, nihonbunka, 日本文化
This blog represents the opinions of the author, Timothy Takemoto, and not the opinions of his employer.